How to Import an External Dataset in EyeOpenR
In today’s interconnected world, data is often collected through a variety of platforms and external applications, tailored to specific industries or operational needs. However, the true value of data lies in its analysis, interpretation, and application. If you’ve gathered your data using an external application, there’s no need to worry about compatibility or usability with our software. In this article, we’ll guide you through the simple steps to import, process, and analyze your externally collected data, demonstrating how our software can help you derive meaningful outcomes, regardless of its origin.
How to import an external dataset


Metadata (optional)
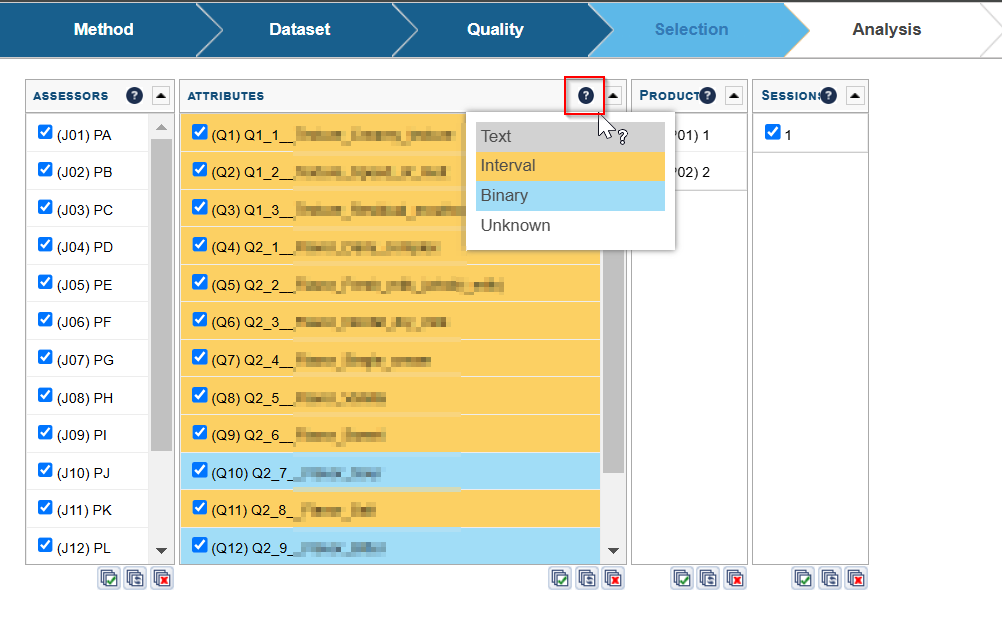
There is a fixed list of datatypes to choose from:
In the Selection screen, the questions will be displayed using different colors, each color representing a datatype, making it easy to identify and adjust the content you want to keep when running your analysis.
How to import an external dataset
Start EyeOpenR using the main menu by clicking on Tools - EyeOpenR. When opening EyeOpenR using the project export menu, data from the project will be pre-loaded. When running EyeOpenR through the main menu, you are able to upload you external dataset.
Select the method you would like to run. If you would like to run an autoreport using an external dataset, you can toggle the switch on the top right of the screen. All available auto reports will be displayed.
Next, in the Dataset screen, you will be able to upload you external dataset. You can do so by clicking the "Add dataset" button. The compatible formats are: xls, xlsx, csv and txt.
Mapping
In order for EyeOpenR to successfully analyze the data that has been collected using an external software, criteria has to be met. The Excel file generated by EOR contains 5 default columns which are mandatory: Assessor, Product, Session, Replica, Sequence. In order for the external dataset to be correctly interpreted, you must use mapping to define your attributes from the external dataset.The meaning of each column and further information about what to expect from them can be read below:
Assessor - this column must be mapped with the panelists column in the external dataset.
Product - sequence of product that the panelists have received the samples.
Session - session number.
Replica - the number of the replica.
Sequence- the sample's position.
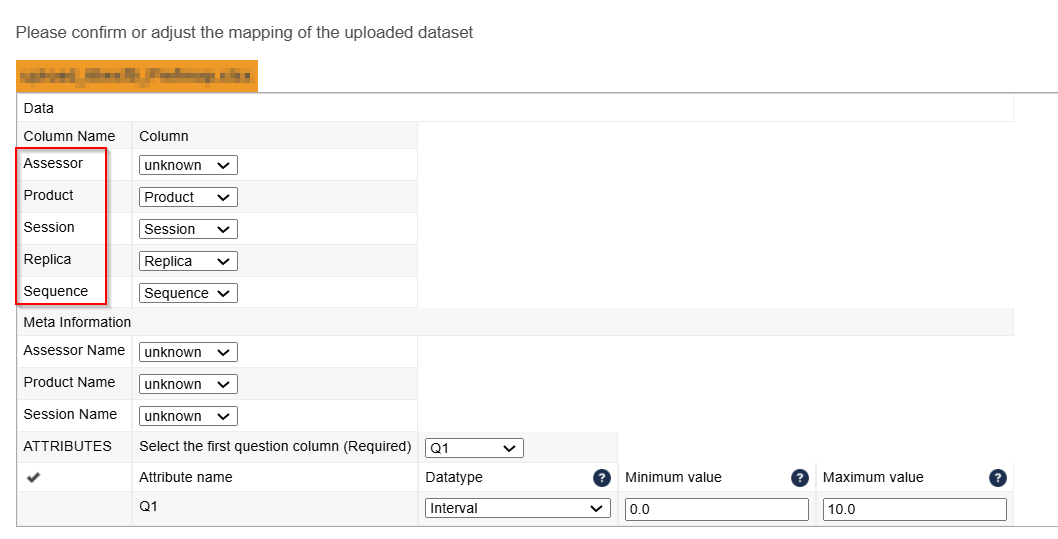
When uploading the dataset in EOR, the software already assigns, by default, the columns according to their content. However, users can verify and adjust the assignment if needed.
Sequence- the sample's position.
When uploading the dataset in EOR, the software already assigns, by default, the columns according to their content. However, users can verify and adjust the assignment if needed.
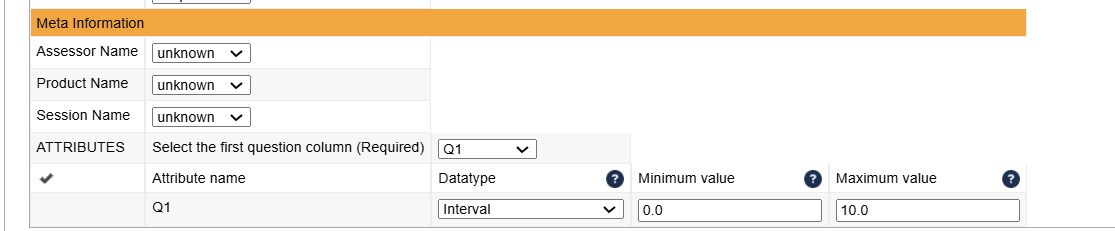
Metadata (optional)
Meta information can be as well mapped as desired by the user, however this step is optional.
In here, you can assign all other columns as well as determine the datatype of the questions. panellist
In here, you can assign all other columns as well as determine the datatype of the questions. panellist
- Nominal: Categorically discrete data such as name of a country, gender etc.
- Ordinal: Quantities that have a natural ordering, e.g. the order of items placed in a line or the ranking of favorite foods. With ordinal data you cannot state with certainty whether the intervals between each value are equal.
- Interval: Similar to ordinal but the intervals between each value are equally split. e.g. data coming from line scales, temperature.
- Comparative: Data from paired comparisons.
- TDS: Temporal dominance of Sensations, contains time related data.
- Napping: Data collected during a Napping test, contains coordinates and words.
- Text: Textual data, e.g. remarks.
- JAR: Just about right data
- Binary: Can be either 1 or 0. Normally this type of data is used in pick any (CATA) data, discrimination test (Triangle, Tetrad etc.) and for true/false questions.
- Tetrad: If you have a Tetrad project, the data type will be automatically tetrad.
Further on, proceed to run the analysis as per usual.
For more information about EyeOpenR and the analyses, please click this link: EyeQuestion | Data Analysis and Exports Knowledge Base
Related Articles
How to run an analysis on an external dataset
An external dataset can be imported into EyeOpenR. This dataset can be used to run analysis or create an autoreport. You can import data in .xls and .xlsx format. Below is a description of the conventional format you can import. This is the format ...EyeOpenR User Guide
EyeOpenR is an advanced statistical analysis and reporting tool integrated within the EyeQuestion software suite. Built on the R statistical language and developed in collaboration with Qi Statistics Ltd., EyeOpenR allows users to perform complex ...How to Import or Update Panellists in Bulk
Import in Bulk Panellists 1. Go to Panel Management and click on ''Import Panellists'' (The option can be used to create new panellists, but also to update existing panellist.) 2. After clicking on import panellists you will land on following page ...Data Cleaning
Introduction Following data collection, it's essential to ensure the validity of the collected data and address any instances where participants may have completed the questionnaire without due attention. To tackle this issue, we've introduced a ...How Can I Analyse My Data?
In EyeQuestion there are multiple options to analyze the project data. When you select the Data tab in your project you will find a dropdown menu Analysis: Auto Reports Via the option for Auto reports EyeQuestion will analyze the data and create the ...